Are you thinking about building a polished AI powered app to explore a large data set? Worried about how to handle data accuracy issues? Do you want to know the pro's and con's of using pgvector with Postgres over a dedicated vector store? Are you interested in hearing tips and tricks for reducing LLM latency? If so then this interview with Luke Van Seters about how he and his team built Zelma is for you! This interview has lots of juicy technical details learnt from shipping a production AI application used by thousands of parents across America.
Zelma Education is a comprehensive, interactive, AI-powered U.S. state assessment data repository that aims to make state assessment data more widely accessible and engaging for the general public. Zelma includes all publicly-available assessment data from all 50 states and D.C. for students in Grades 3-8.
Luke is the co-founder of Novy a consultancy focused on building generative AI applications. Prior to Novy Luke was an Entrepreneur In Residence at Paradigm and a Staff Software Engineer at Drift where he solved complex backend engineering problems.
Zelma was developed with Novy in conjunction with Emily Oster an economist at Brown University and a bestselling author known for her work in parenting. She has a significant online presence, particularly through her Substack newsletter, where she shares data-driven insights on parenting and education. Her work aims to make complex data accessible and useful for parents and educators.
Check out the video for the complete interview, but here are some of the highlights:
Project Background
- Emily Oster's team collected data on school closures and virtual schooling during COVID-19.
- The data was made accessible to researchers and the general public.
- Novy's task was to create an AI-driven, user-friendly interface for querying this data.
Initial Steps
- Emily Oster's team collected data on school closures and virtual schooling during COVID-19.
- Novy quickly developed a prototype within 24 hours using Python and SQL.
- Early feedback identified issues with the accuracy and speed of queries.
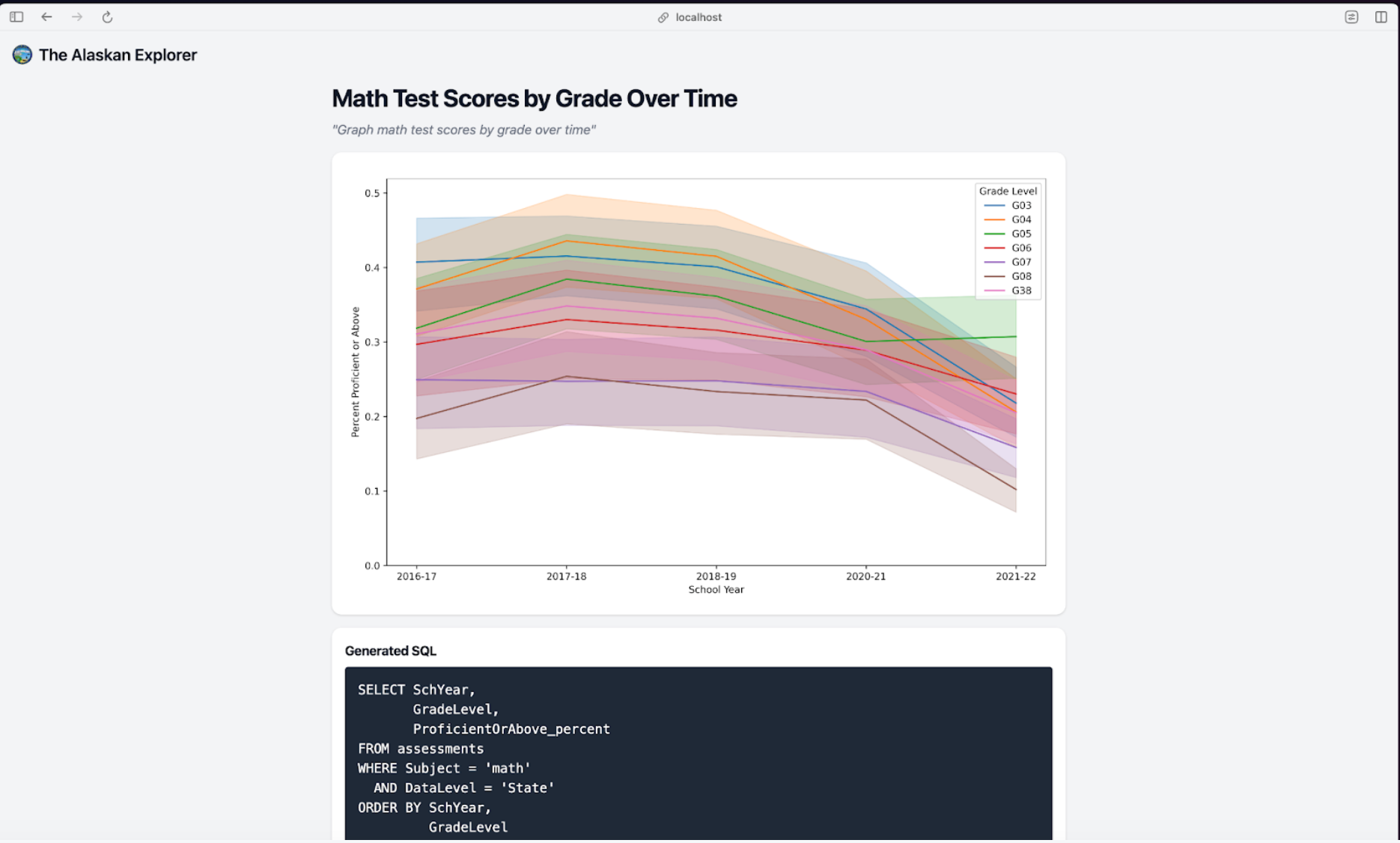
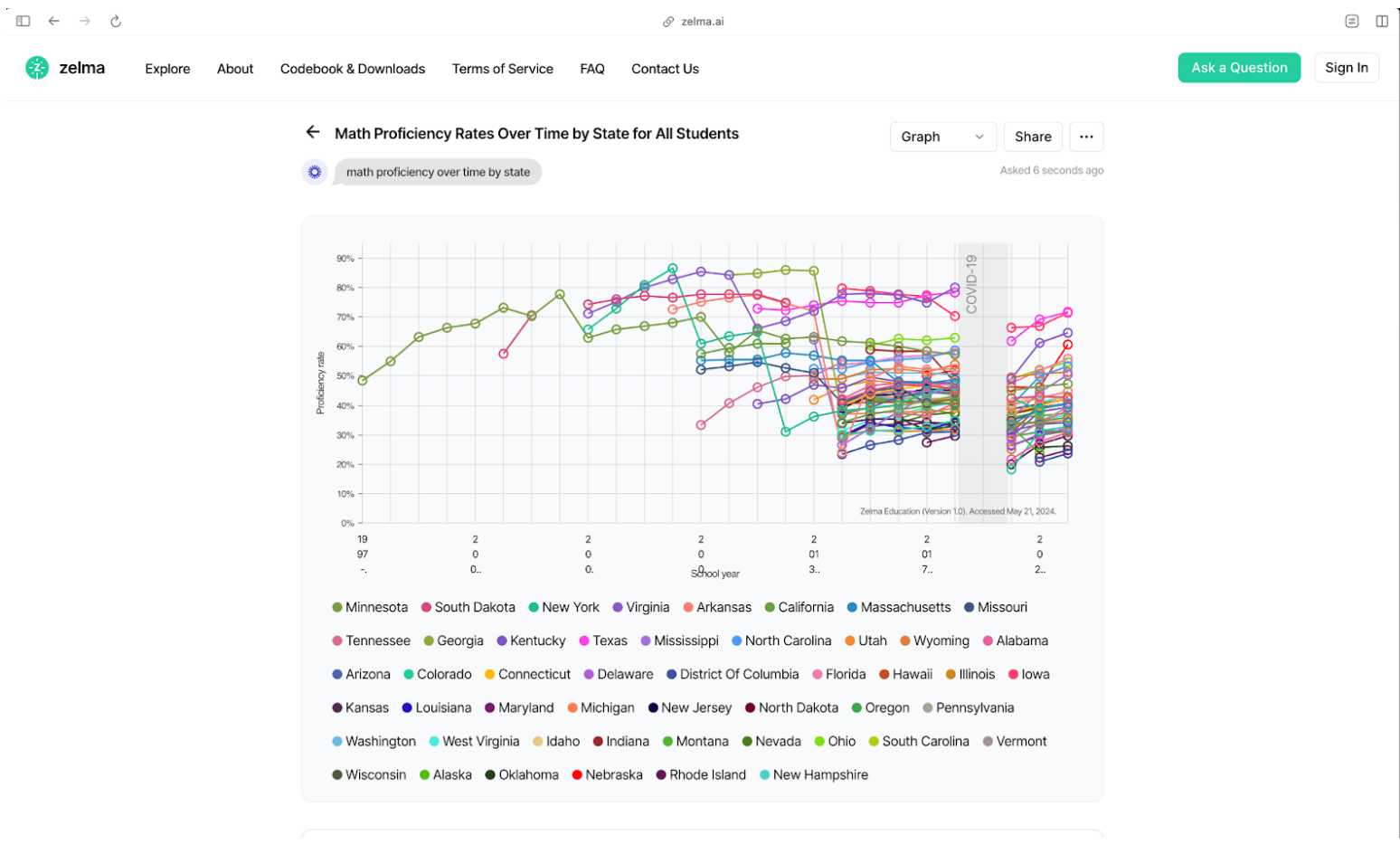
Challenges and Solutions
- Accuracy Issues: Data partitioning and denormalization led to incorrect results. Solution involved creating a structured JSON schema for queries.
- Speed Issues: Initial queries took 30-40 seconds. Optimization techniques, such as reducing token usage in LLM outputs and breaking queries into smaller parts, reduced this to under 5 seconds.
Technical Details
- Stack: GCP, Kubernetes, FastAPI, Celery, Next.js, OpenA, pgvector and Postgres.
- Optimization: Use of embeddings for vector search, query planning, and parallelization to speed up LLM responses.
- Database War Stories: Initial high traffic led to 100% CPU usage on Postgres. Solved by indexing and vacuuming the database.
Future Considerations
- Database Migration: Potential move from Postgres to ClickHouse for better handling of large-scale analytics queries.
- Open-source Models: Discussion on hosting open-source models for better control over generation processes and cost savings.
- Evaluation Frameworks: Use of RAGAS for evaluating LLM responses and considering other frameworks for future projects.