TL;DR: Amazon Aurora extends PostgreSQL with better scalability and performance, enabling efficient autoscaling and Serverless options. However, it faces challenges with complex pricing and vendor lock-in. This article helps navigate those issues.
Introduction
As your PostgreSQL application grows in scale, whether you choose to self-host or opt for a managed service like Amazon RDS, it may become bottlenecked. However, traditional scaling approaches can be complex and disruptive, leading to performance issues, downtime, and increased costs.
That's where Amazon Aurora comes in, by separating storage from compute, Aurora enables greater throughput and availability compared to plain RDS. Additionally, its autoscaling and serverless capabilities, combined with usage-based pricing, can provide a more efficient and cost-effective solution.
As an example, vertical scaling, whether in self-hosted or managed environments, can be a complex and disruptive process, requiring careful planning and execution to avoid downtime and data loss. Moreover, instance size limits can become a bottleneck as your workload grows, leading to:
- Performance issues due to high traffic or large datasets
- Downtime during maintenance and upgrades
- Limited scalability and availability across regions
- Increased costs for hardware and administrative overhead
Imagine your application is running smoothly, using a database hosted on a traditional server or even an RDS instance. But then, traffic spikes – caused by a new marketing campaign, a post on Hacker News or a holiday rush. Suddenly, your database struggles to keep up, queries slow down, and your application grinds to a halt. This downtime translates to lost revenue and frustrated users.
In this article, we'll explore the Pro’s and Con’s of using Amazon Aurora, a PostgreSQL compatible solution, to overcome vertical scaling limitations.
Aurora Overview
Aurora is a database as a service (DBaaS) product released by AWS in 2015. At its core, Aurora separates the compute resources (CPU and RAM) from the storage layer. This decoupled architecture is quite different from monolithic databases where the compute and storage layers are tightly coupled.
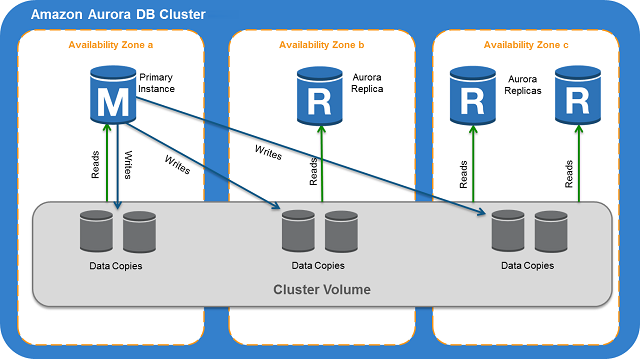
With Aurora, the compute layer is made up of one or more "Aurora Instances" - these are essentially the database servers or nodes that run the database engine and handle query processing, just like EC2 instances.
The storage layer is called the "Aurora Cluster Volume" - this is a virtualized, network-attached storage volume that contains your actual data. It's designed to be highly available, and durable, leveraging redundant copies across multiple Availability Zones.
Aurora's architecture is particularly well-suited for horizontal scalability because it allows you to easily add or remove Aurora Instances as needed, without affecting the underlying storage layer. This means you can quickly scale your database to handle changes in traffic or workload, without worrying about running out of storage space or having to migrate data to a new instance. Additionally, the Aurora Cluster Volume's redundant copies across multiple Availability Zones ensure that your data is always available, even in the event of an instance failure or network partition. This makes it easy to scale your database across multiple regions, without sacrificing performance or availability
With the latest version, Aurora Serverless v2, you can enjoy automatic scaling of capacity based on application demand, making it even easier to manage your database resources. This means you can focus on developing your application without worrying about manually scaling your database to match changing workloads.If you want a deeper dive into Aurora’s architecture, AWS published a paper describing it which you can read here.
Originally, Amazon Aurora only supported MySQL, but PostgreSQL support was added in 2017. Aurora addresses the challenges outlined in the introduction by offering:
- High-performance capabilities, it claims to be up to three times the throughput of RDS PostgreSQL
- Multi-region clusters for enhanced availability and scalability
- Serverless options (Aurora Serverless and Serverless v2) for cost-effective scaling
Aurora is PostgreSQL-compatible, meaning it supports the same SQL syntax and offers similar functionality, but it is a proprietary database engine that's not open-source like PostgreSQL. This means that in addition to it being not possible to self host or migrate to other hosting providers you also have limited visibility into its internals and no ability to make changes to them.
Challenges in Modeling Aurora Pricing
Aurora offers two main pricing options: Provisioned and Serverless. Provisioned instances have a fixed hourly cost based on the chosen instance class, while Serverless pricing is usage-based. Serverless can be cost-effective for workloads with quiet periods, but may not be ideal for consistently high workloads.
When selecting Serverless, you set a range of resources in Aurora Capacity Units (ACUs), which determines the resources your cluster will use. However, understanding ACUs is challenging, making it difficult to model Serverless pricing. The opacity of ACUs is frustrating, as it's unclear what "corresponding compute and networking" resources are included in the 2 GiB of memory per ACU.
A comment on a post in r/PostgreSQL provides the following description of what an ACU is (based on a call with AWS Support) so you get a flavor of why price comparison can be tricky:“"An ACU is roughly .25 a vCPU. So, running a max 128 ACU gives a ceiling of 32 vCPU with 256GB of RAM. They won't say it in marketing. But I've benchmarked Aurora a lot. It generally takes a 2 hour benchmark of incremental increase in load to achieve close to 32 vCPU as seen in aws performance insights. At that point, my benchmark process is running around 200k queries per second of oltp workload, insert heavy, but update,delete, select is represented too. For the same workload on RDS, I don't have to baby it as the warm up period is minimal. Performance is more consistent in RDS."
This opacity around ACU’s makes it hard to reason about the cost of Aurora as it scales up to meet spikes in traffic with the serverless option. In addition to this, it’s important to note that Aurora’s Serverless pricing model does not offer the ability scale to zero unlike other serverless offerings such as Neon’s. There is a minimum of 0.5 ACUs. This functionality was previously available with Aurora Serverless v1, however v1 will no longer be supported as of December 31, 2024.
Modeling Aurora pricing can be hard due to:
- Variable usage patterns: Workloads can vary significantly, making it difficult to estimate costs.
- Complex pricing tiers: Multiple pricing tiers and discounts can apply, depending on usage levels.
- Regional pricing differences: Prices vary across AWS regions, adding complexity to cost estimates.
- Storage and I/O costs: Estimating storage and I/O costs can be challenging, especially for dynamic workloads.
- Serverless pricing opacity: The lack of clarity around ACU definitions and corresponding compute and networking resources makes it difficult to accurately model Serverless pricing.
Additional Factors to Consider
- Reserved Instances: Discounts for committed usage can reduce costs, but require upfront payments.
- Data transfer costs: Data transfer between regions or services can incur additional costs.
- Backup and restore costs: Backup storage and restore operations can add to overall costs.
So how much will it cost to run your application on Aurora? Well, that depends on what your application does of course. If you google around for examples of Aurora pricing, especially ones that compare it to other Serverless options you will get conflicting messages. As an example, let’s look at one simplistic comparison between Aurora, Timescale and Neon on r/PostgreSQL:
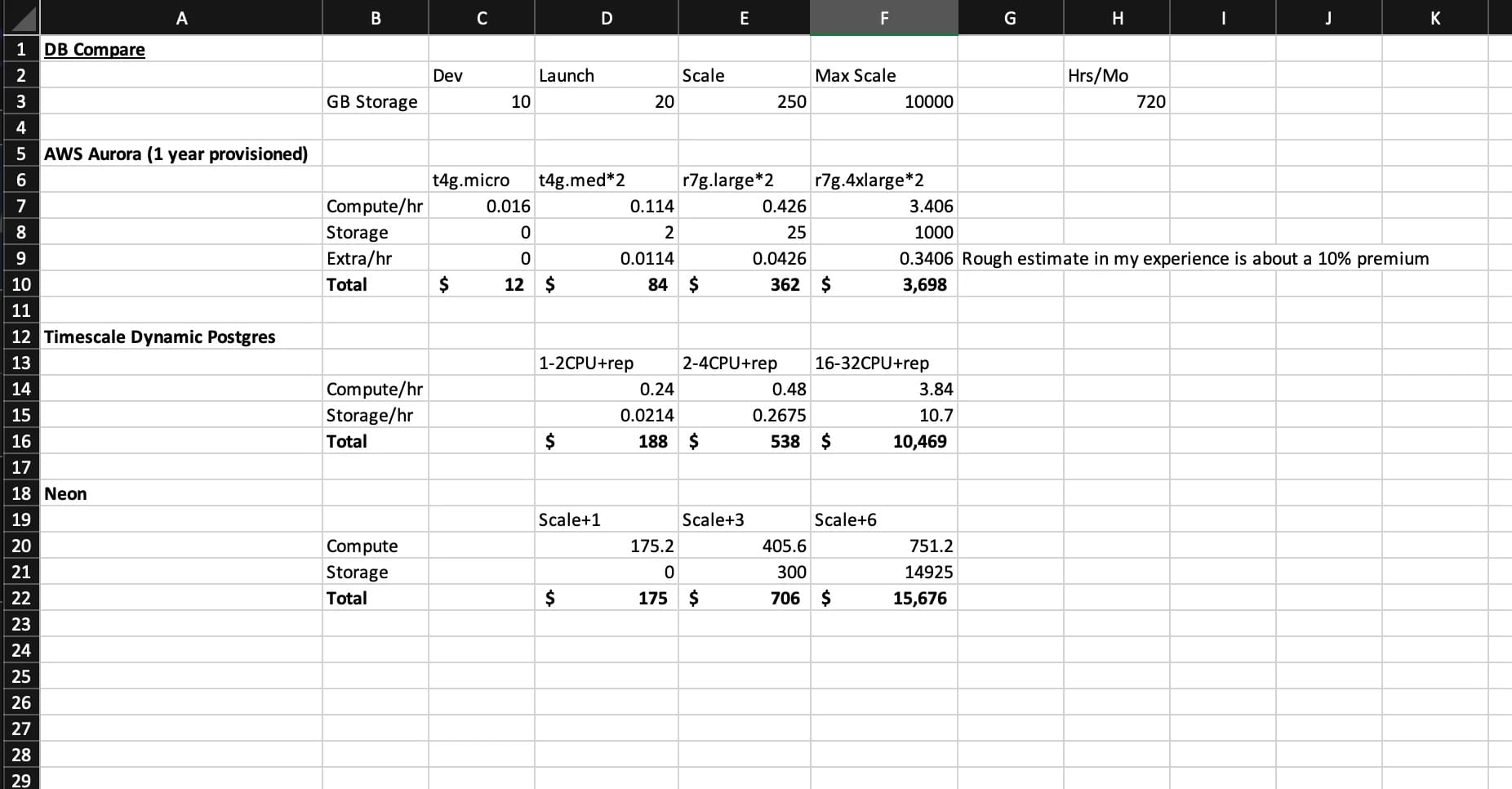
This price comparison makes a compelling case for Aurora assuming at scale you need to run a system at 100% or more of this modeled capacity and need to use a large amount of storage for a year. Which for many use cases may not be the case. If you’re a business with seasonal usage patterns that doesn’t need that much space or compute for most of the year like say an educational startup, then this might change your calculations considerably to favor the other options being compared.
To give another example let’s look at this article from Vantage comparing Aurora to Neon in 3 different scenarios:
- Scenario One: Testing Environment For a Web Application: Say you have a web application and need testing environments to validate new features and conduct performance testing. The team’s performance testing environment is idle for 4/5ths of the time. During the remaining time, the workload alternates between low and extra low compute requirements. In this scenario, Neon’s compute is 20% less than Aurora’s. That cost can add up when you consider other testing, development, staging, etc., environments.
- Scenario Two: Social Media Analytics Platform: A small social media analytics platform continuously collects certain data from various social media platforms. The compute varies throughout the day but is rarely idle. During off-peak hours, the system operates with 1 ACU/CU of compute capacity. During peak hours, the compute capacity scales up to 6 ACUs/CUs. The I/O usage is moderate so we can still use Aurora Standard. In this scenario, Aurora costs 25% less comparedfor compute than Neon.
- Scenario Three: Batch Data Processing System: A batch data processing system ingests data in batches at regular intervals, processes it to extract insights, and stores the results in a database for further analysis. It will be idle at times and can be categorized as an I/O-intensive application. The team uses Aurora I/O-Optimized to save on I/O costs. The system is idle 2/3rds of the time and uses high compute (corresponding to 8 ACUs/CUs) the rest of the time. Neon’s compute is 11% less expensive in this scenario.
In addition to these scenarios, Timescale, a company selling a time series database built on PostgreSQL has an excellent blog post that digs into this subject and walks you through the different Aurora options and how they compare to their product which you can read here.
They used their own Time Series Benchmark Suite (TSBS) to compare Amazon Aurora to PostgreSQL because they wanted to benchmark for a specific workload type (in this case, time series data), which again, may not be relevant to the job you want to do. According to their findings, the Timescale solution was:
- 35 % faster to ingest
- 1.15x-16x faster to query in all but two query categories
- 95 % more efficient at storing data
- 52 % cheaper per hour for compute
- 78 % cheaper per month to store the data created
Considering these factors, modeling Aurora pricing requires a detailed understanding of your workload, usage patterns, and pricing nuances to ensure accurate cost estimates. Ideally this would be done by an experienced engineer who understands the product you are building, the business challenges you are trying to meet and architectural challenges you are likely to face as you scale. This is something that StepChange can help you understand and optimize via our performance assessment package.
Aurora Pros And Cons
To finish out this article I put together some high level Pro’s and Con’s you might want to consider when it comes to adopting Aurora.
Aurora Pros:
- High Performance: Aurora boasts impressive performance compared to other database options. According to AWS, it can deliver up to 5 times the throughput of standard MySQL databases and up to 3 times the throughput of Amazon RDS PostgreSQL without requiring significant code modifications to your existing application. This translates to faster query processing and a smoother user experience for your application.
- Durability: Aurora's distributed storage architecture and automatic failover features ensure high availability and data durability. Even if one server experiences an issue, your database remains operational thanks to automatic failover to a healthy replica.
- Scalability: Scaling limitations can hinder growth. Aurora's auto-scaling capabilities allow it to seamlessly adjust resources based on your workload demands. This ensures your database has the power it needs to handle traffic spikes or increased data volume without manual intervention.
- Compatibility: Migrating to a new database can be daunting. Aurora's compatibility with PostgreSQL allows you to leverage your existing PostgreSQL code and skills with minimal adjustments. This minimizes migration complexity and allows you to focus on application development.
- Managed Service: Aurora is a fully managed service, freeing up resources for more strategic tasks.
- Support for Extensions: Extend functionality when needed. While not all PostgreSQL extensions work seamlessly with Aurora, it does support a variety of popular extensions, including pg_vector for spatial data manipulation. This allows you to leverage additional functionalities for your specific needs.
Aurora Cons:
- Complexity: Aurora's pricing and performance nuances can be challenging to understand and optimize.
- Cost: Aurora can be expensive, especially for large or high-performance instances. Also, with Aurora Serverless v1 being no longer be supported as of December 31, 2024, you can no longer scale to 0.
- Serverless Opacity: The lack of clarity around ACUs and corresponding resources makes Serverless pricing difficult to model.
- Regional Dependencies: Aurora prices and features vary across regions, requiring careful planning for multi-region deployments.
- Lock-in: Using Amazon Aurora can significantly limit flexibility due to vendor lock-in. Aurora's closed-source engine, built specifically for AWS, complicates migration efforts to other platforms because of its unique data replication and storage techniques. In addition, the fact that it’s proprietary means that you are dependent on AWS’s priorities for fixes and adopting new versions of PostgreSQL.
- Aurora Is Not PostgreSQL: Aurora is PostgreSQL compatible but not actually PostgreSQL. Hence some extensions might not be supported, and upgrading to a new major version may remove support for certain extensions. See here for an example of this. Also, Aurora only supports specific PostgreSQL versions, and upgrading to a new major version can be disruptive.
If you need to scale your PostgreSQL databases to meet growing demands without sacrificing performance, our team is ready to assist. We specialize in designing scalable data architectures that balance efficiency and flexibility. Contact us to learn how we can help you build a robust, cost-effective PostgreSQL solution. In the next article in this series, we will be exploring the Pro’s and Con’s of Neon, a serverless Postgres alternative to AWS.